


我院袁春教授團隊在長尾數據下的標簽噪聲問題的最新研究成果,以“When Noisy Labels Meet Long Tail Dilemmas: A Representation Calibration Method”為題,被計算機視覺領域世界三大頂級會議之一的ICCV 2023錄用,獲得最佳論文提名獎。ICCV 2023有效投稿數為8260篇,其中最佳論文提名的僅有17篇(入選率0.2%)! ICCV,英文全稱International Conference on Computer Vision,中文全稱國際計算機視覺大會,由IEEE主辦,每兩年在世界范圍內召開一次,得到世界各地研究者的高度認可。
深度學習在許多領域取得了快速進展,這很大程度得益于大規模和高質量的標注數據集,而在現實中我們很難獲得如此完美的數據集。這來源于兩個方面,一是部分數據標注錯誤,二是數據類別不平衡,呈現出長尾分布。在現實環境中,兩種不完美的情況通常同時存在。深度神經網絡具有強大的擬合能力。網絡在帶有不平衡且帶錯誤標簽的數據集上進行訓練,會導致網絡過擬合,進而嚴重降低模型的泛化性能。雖然長尾分布學習和標簽噪聲學習都已經有了一定的研究,但是這種更加實際且具有挑戰性的長尾數據下的標簽噪聲任務卻未被充分探索。
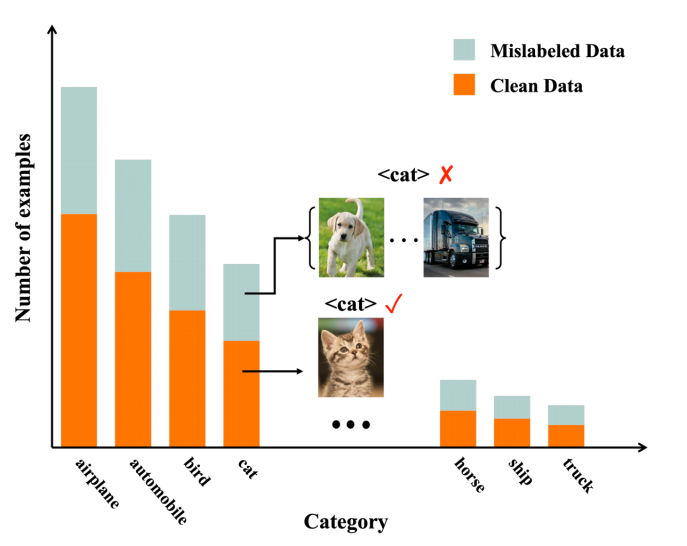
圖1 長尾數據下的標簽噪聲問題示意圖
最直觀解決這個復合問題的方法是將標簽噪聲學習的算法和長尾數據學習算法進行復合。然而通過調研相關文獻,發現算法的簡單復合并不能有效解決這一具有挑戰性問題,主要有以下挑戰點:(1)如何在帶有錯誤標注的數據中去學習到“真實”的長尾數據分布。(2)如何將尾部類數據與錯誤標注的樣本進行區分。因此,針對以上挑戰,袁春教授團隊提出了深層表征校準方法RCAL。該方法的目的是希望從深層表征的角度去還原潛在的平衡且干凈的數據分布,并提供正確的信息幫助網絡訓練。
該研究的方法由三部分組成:對比學習預訓練、分布校準和個體校準。
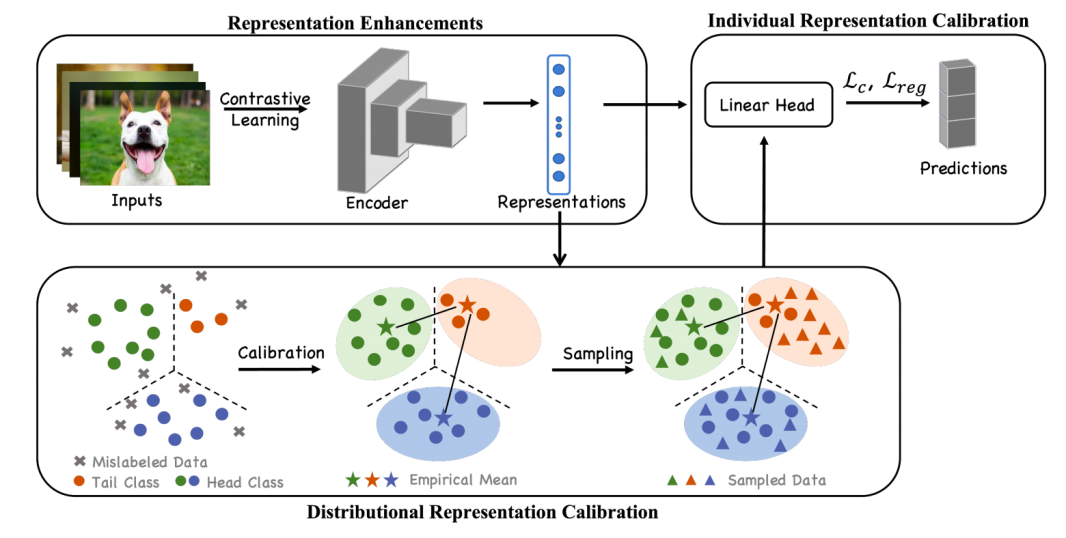
圖2 算法總流程示意圖
第一步,采用對比學習進行預訓練以獲得原始數據的深層表征,該表征可以捕獲同一類內的相似特征并學習不同類之間的可鑒別特征。使用對比學習的原因是,它是一種自監督的方法,不受噪聲標簽的影響。此外,其學習到的特征可以表現出聚類特性,為后續操作提供支持。
第二步,經過對比預訓練后,進行分布校準以減輕噪聲標簽和長尾問題。該方法基于這樣的假設:在數據污染之前,每個類數據的深層表征滿足一個多元高斯分布。基于此,可以估計每個類別的均值和協方差矩陣,以進行后續的校準。
具體來說,首先在深層表征上使用異常值檢測算法,以識別可能不正確的標注數據并將其刪除。然后,可以估計每個類別的均值和協方差矩陣。對于樣本量較小的尾部類,進一步使用與其接近的頭部類信息來幫助其估計。獲得每一類分布后,對這些高斯分布進行重新采樣,以減輕類別不平衡。
第三步,聯合采樣數據和原始數據集訓練最終的分類器。同時,將fine-tune得到的表征與對比學習學到的表征的距離作為正則化項,以保留通過對比學習學到的知識。最終的目標函數是在校準數據集上評估的交叉熵損失加上正則化項。
從實驗上,在合成的CIFAR-10和 CIFAR-100數據集上,該研究觀察到在不同的噪聲率和不平衡率下,RCAL幾乎可以超越所有基線。隨著任務更具挑戰性,RCAL表現出更明顯的優勢。
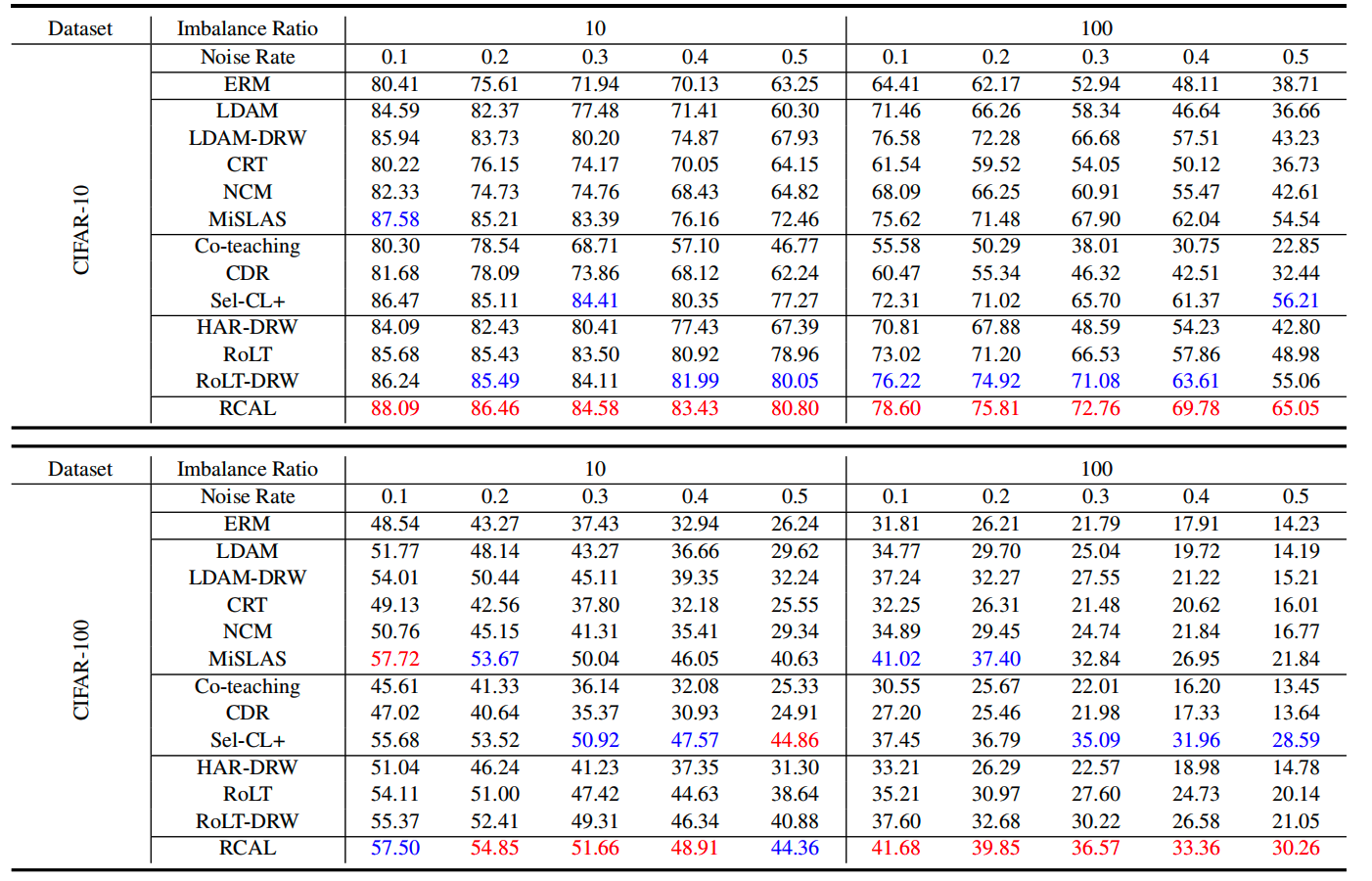
圖3 CIFAR-10、CIFAR-100 合成數據下的測試準確度
在真實數據集上可以看出,與其他最先進的方法相比,RCAL+在 WebVision驗證集和 ImageNet ILSVRC12驗證集上均取得了最佳結果。
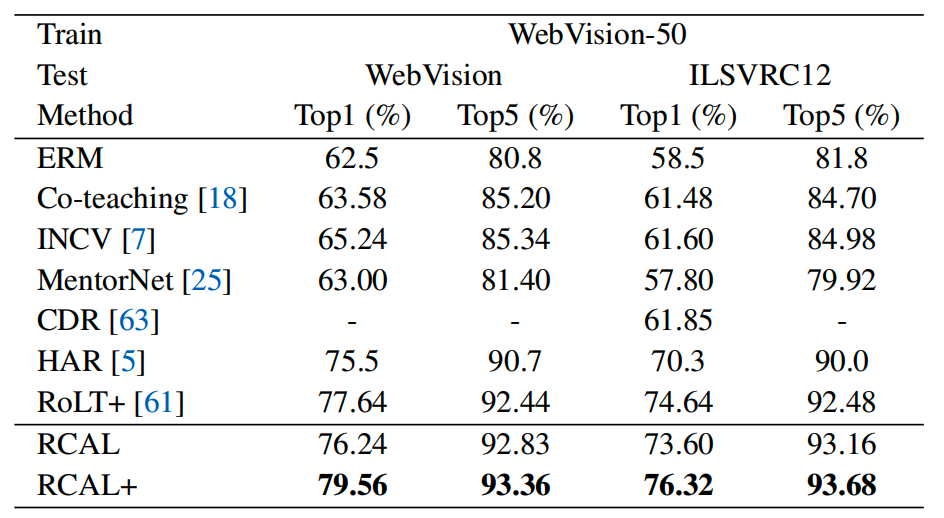
圖4 WebVision和ImageNet ILSVRC12 的測試準確度
該研究進行了多種消融實驗,探究算法有效的原因。
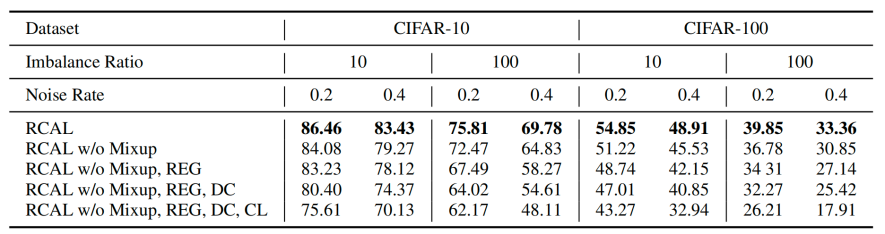
圖5 消融實驗
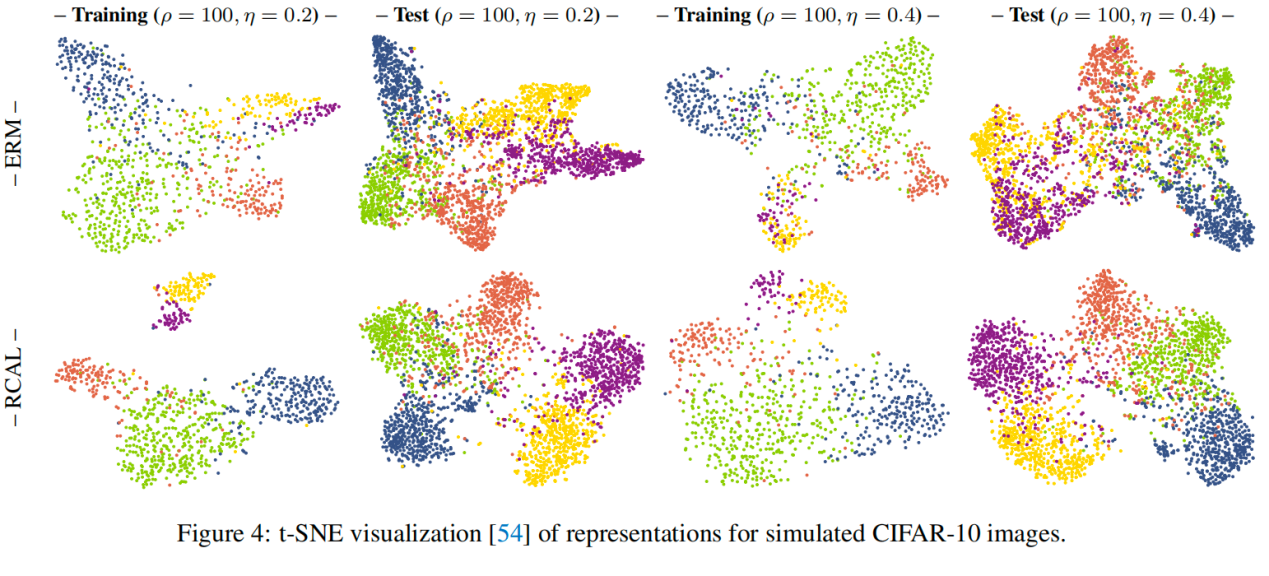
圖6 t-sne 可視化下的表征

圖7 ICCV 2023論文獲獎候選列表
我院2021級碩士生張曼怡為該文章的第一作者,通訊作者為袁春教授,論文共同作者還包括上海交通大學黃維然副教授、華為諾亞方舟實驗室姚駿、北京大學博士生趙旭陽。
論文鏈接:
文/圖:張曼怡
編輯:萬欣宜
審核:陳超群
